
一键etcd快速备份与恢复脚本
写在最前
服务器只要来一次意外宕机etcd它大概率就会损坏启动不起来,没有备份的你只能提桶跑路了。在此情景我们必须要掌握备份和恢复etcd的技能。
1. 前置环境
为了模拟etcd损坏无法恢复的情况,我们需要准备一个纯净的 k8s 环境。
2. 主机备份
2.1 快速备份
无论是集群还是单机etcd中的内容都是一致彼此同步的,通常会使用定时任务每隔xx小时xx分钟备份一次快照文件。
注意设置 etcd 证书路径,你的证书名称和我的可能会不一样,要检查配置好脚本。
#!/bin/bash
SERVICE_NAME="etcd"
# 检查服务是否在运行
if systemctl is-active --quiet $SERVICE_NAME; then
echo "$SERVICE_NAME is running."
else
echo "$SERVICE_NAME is not running."
exit 1
fi
# 获取当前主机的 IP 地址
CURRENT_IP=$(hostname -I | cut -d' ' -f1)
# 设置备份存储路径
BACKUP_DIR="/root/etcd-backup"
# 设置 etcd 证书路径
CACERT="/etc/ssl/etcd/ssl/ca.pem"
CERT="/etc/ssl/etcd/ssl/admin-master1.pem"
KEY="/etc/ssl/etcd/ssl/admin-master1-key.pem"
# 检查备份目录是否存在,如果不存在则创建
if [ ! -d "$BACKUP_DIR" ]; then
mkdir -p "$BACKUP_DIR"
fi
# 获取当前时间的年、月、日、小时和分钟
YEAR=$(date +"%Y")
MONTH=$(date +"%m")
DAY=$(date +"%d")
HOUR=$(date +"%H")
MINUTE=$(date +"%M")
# 构建格式化的时间戳
TIMESTAMP="${YEAR}年${MONTH}月${DAY}日${HOUR}时${MINUTE}分"
# 构建备份文件名
BACKUP_FILE="$BACKUP_DIR/etcd_backup_$TIMESTAMP.db"
# 执行 etcd 备份命令
ETCDCTL_API=3 /usr/local/bin/etcdctl --endpoints="https://$CURRENT_IP:2379" snapshot save "$BACKUP_FILE" \
--cacert="$CACERT" \
--cert="$CERT" \
--key="$KEY"
if [ $? -eq 0 ]; then
echo "Backup successful: $BACKUP_FILE"
else
echo "Backup failed"
fi
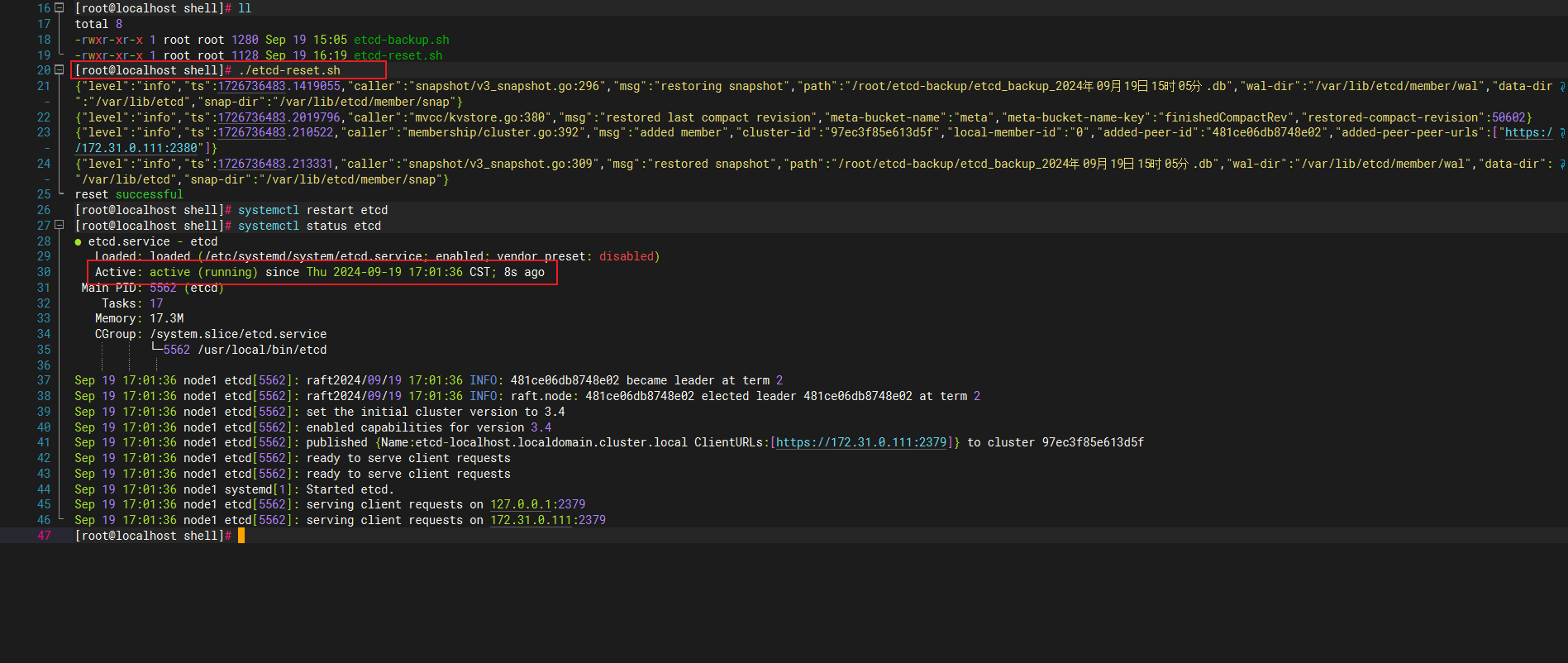
可以看到成功通过脚本备份出etcd的db快照文件了。
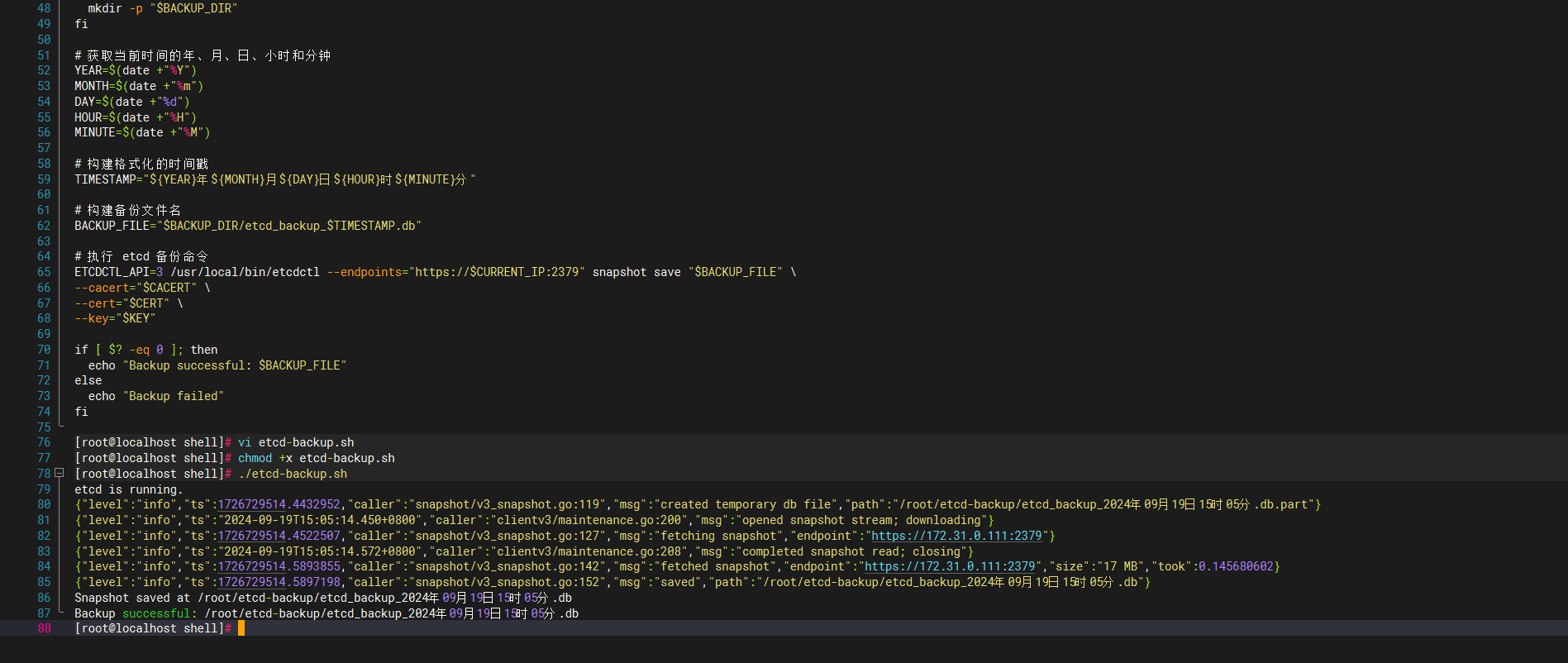
2.2 etcd单机还原
我长按笔记本电脑开机按钮几秒强制关机模拟服务器断电宕机,可以看到启动完linux后etcd已经死透了,此操作非常危险如果你没有备份 etcd 那你的环境就死定了。
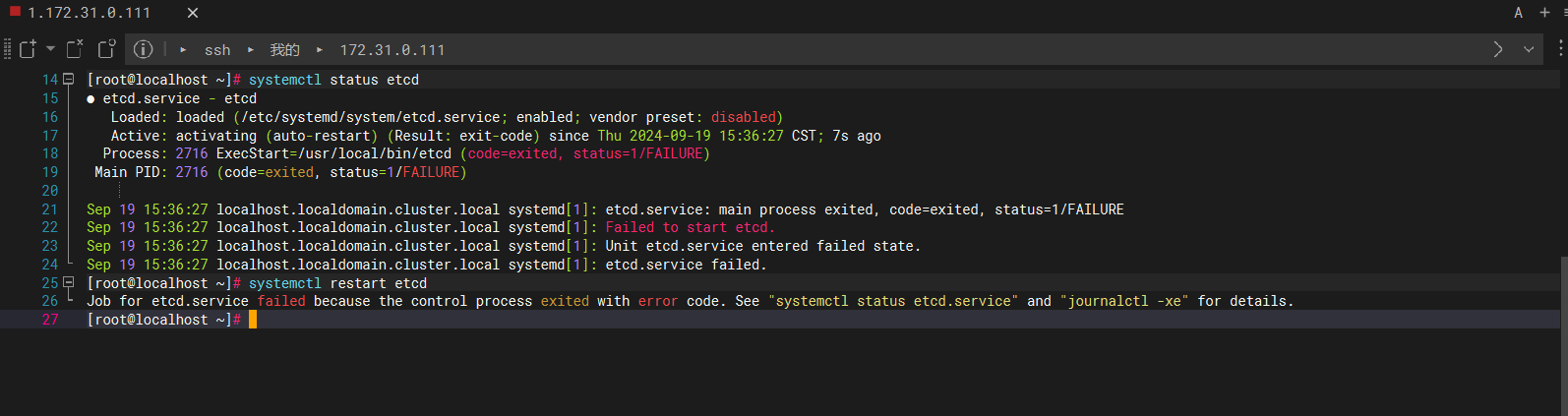
注意,还原脚本中我写的上来直接删除etcd数据目录,因为实在启动不起来而且我也事先做好备份了。
脚本中的 HOSTNAME 可以在 /etc/hosts 中看到,因为我是单节点k8s所以只有一个,你的环境要按实际内容调整。
#!/bin/bash
#删除之前的,也不备份了!!!
rm -rf /var/lib/etcd
# 获取当前主机的 IP 地址
CURRENT_IP=$(hostname -I | cut -d' ' -f1)
#HOSTNAME=$(hostname)
HOSTNAME="localhost.localdomain.cluster.local"
# 构建自动添加端口的 peer 地址
PEER_URL="https://${CURRENT_IP}:2380"
# 定义 etcd 集群的初始成员信息
INITIAL_CLUSTER="${HOSTNAME}=https://${CURRENT_IP}:2380"
# 定义 etcd 集群的初始成员令牌
INITIAL_CLUSTER_TOKEN="etcd-cluster"
# 设置恢复快照文件
BACKUP_FILE="/root/etcd-backup/etcd_backup_2024年09月19日15时05分.db"
# 设置 etcd 证书路径
CACERT="/etc/ssl/etcd/ssl/ca.pem"
CERT="/etc/ssl/etcd/ssl/admin-node1.pem"
KEY="/etc/ssl/etcd/ssl/admin-node1-key.pem"
ETCDCTL_API=3 etcdctl snapshot restore $BACKUP_FILE \
--name $HOSTNAME \
--cacert "$CACERT" \
--cert "$CERT" \
--key "$KEY" \
--initial-cluster "$INITIAL_CLUSTER" \
--initial-cluster-token etcd-cluster \
--initial-advertise-peer-urls "$PEER_URL" \
--data-dir=/var/lib/etcd
if [ $? -eq 0 ]; then
echo "reset successful"
else
echo "reset failed"
fi
2.3 etcd集群还原
在恢复 etcd 集群时直接写死固定节点的 IP 地址和名称是一种快速且直接的方法,尤其是当你对集群的配置非常熟悉,我嘛就直接这样写了。
#!/bin/bash
#删除之前的,也不备份了!!!
rm -rf /var/lib/etcd
# 获取当前主机的 IP 地址
CURRENT_IP="172.31.0.31"
HOSTNAME="node1"
# 构建自动添加端口的 peer 地址
PEER_URL="https://172.31.0.31:2380"
# 定义 etcd 集群的初始成员信息
INITIAL_CLUSTER="node1=https://172.31.0.31:2380,node2=https://172.31.0.32:2380,node3=https://172.31.0.33:2380"
# 定义 etcd 集群的初始成员令牌
INITIAL_CLUSTER_TOKEN="etcd-cluster"
# 设置备份存储路径
BACKUP_FILE="/root/etcd-backup/etcd_backup_2024年09月19日15时05分.db"
# 设置 etcd 证书路径
CACERT="/etc/ssl/etcd/ssl/ca.pem"
CERT="/etc/ssl/etcd/ssl/admin-node1.pem"
KEY="/etc/ssl/etcd/ssl/admin-node1-key.pem"
ETCDCTL_API=3 etcdctl snapshot restore $BACKUP_FILE \
--name $HOSTNAME \
--cacert "$CACERT" \
--cert "$CERT" \
--key "$KEY" \
--initial-cluster "$INITIAL_CLUSTER" \
--initial-cluster-token etcd-cluster \
--initial-advertise-peer-urls "$PEER_URL" \
--data-dir=/var/lib/etcd
if [ $? -eq 0 ]; then
echo "reset successful"
else
echo "reset failed"
fi
3. 容器备份
3.1 脚本
etcd-backup.sh
该备份脚本需部署并运行在 Master 节点 上。
由于集群采用 kubeadm 方式搭建,etcd Pod 的命名规则与宿主机 NodeName(主机名)保持一致,因此脚本可基于当前主机名对 etcd Pod 进行精确过滤。
脚本在执行时会自动获取当前主机的主机名,并仅选择 运行在该节点上的 etcd Pod 进行操作,从而确保备份操作始终作用于 本机对应的 etcd 实例
#!/bin/bash
set -euo pipefail
# ================== 配置区 ==================
NAMESPACE="kube-system"
BACKUP_DIR="/data/backup/etcd-backup"
ETCDCTL_API=3
CACERT="/etc/kubernetes/pki/etcd/ca.crt"
CERT="/etc/kubernetes/pki/etcd/server.crt"
KEY="/etc/kubernetes/pki/etcd/server.key"
# ================== 基础检查 ==================
command -v kubectl >/dev/null 2>&1 || {
echo "[ERROR] kubectl not found"
exit 1
}
mkdir -p "${BACKUP_DIR}"
# ================== 找 etcd Pod(仅当前节点) ==================
NODE_NAME=$(hostname)
ETCD_POD=$(kubectl -n ${NAMESPACE} get pods \
-l component=etcd \
--field-selector spec.nodeName=${NODE_NAME} \
-o jsonpath='{.items[0].metadata.name}')
[ -n "${ETCD_POD}" ] || {
echo "[ERROR] etcd pod not found on node ${NODE_NAME}"
exit 1
}
echo "[INFO] using etcd pod: ${ETCD_POD} on node ${NODE_NAME}"
# ================== 文件名 ==================
TIMESTAMP=$(date +"%F-%H%M%S")
SNAPSHOT_FILE="/var/lib/etcd/snapshot-${TIMESTAMP}.db"
# ================== 执行备份 ==================
kubectl -n ${NAMESPACE} exec "${ETCD_POD}" -- sh -c "
ETCDCTL_API=${ETCDCTL_API} etcdctl snapshot save ${SNAPSHOT_FILE} \
--endpoints=https://127.0.0.1:2379 \
--cacert=${CACERT} \
--cert=${CERT} \
--key=${KEY}
"
# ================== 校验 snapshot ==================
kubectl -n ${NAMESPACE} exec "${ETCD_POD}" -- sh -c "
ETCDCTL_API=${ETCDCTL_API} etcdctl snapshot status ${SNAPSHOT_FILE}
"
# ================== 移动到备份目录 ==================
mv "${SNAPSHOT_FILE}" "${BACKUP_DIR}/"
echo "[SUCCESS] etcd backup completed: ${BACKUP_DIR}/$(basename ${SNAPSHOT_FILE})"
# ================== 保留最近 N 个快照 ==================
KEEP_COUNT=7
cd "${BACKUP_DIR}"
OLD_SNAPSHOTS=$(ls -1t snapshot-*.db 2>/dev/null | tail -n +$((KEEP_COUNT + 1)))
if [ -n "${OLD_SNAPSHOTS}" ]; then
echo "[INFO] deleting old snapshots:"
echo "${OLD_SNAPSHOTS}"
rm -f ${OLD_SNAPSHOTS}
else
echo "[INFO] no old snapshots to delete"
fi3.2 定时配置
# 直接编辑
crontab -e
# 每天 00:00 执行
0 0 * * * /app/script/etcd-backup.sh >> /var/log/etcd-backup.log 2>&14. 异常解决
4.1 connect: no route to host
[root@localhost shell]# kubectl logs -n kubesphere-system ks-controller-manager-5fbf7f9b9f-8vht4
W0919 16:30:58.374922 1 client_config.go:615] Neither --kubeconfig nor --master was specified. Using the inClusterConfig. This might not work.
I0919 16:30:58.376103 1 server.go:202] setting up manager
E0919 16:30:59.378441 1 deleg.go:144] "msg"="Failed to get API Group-Resources" "error"="Get \"https://10.233.0.1:443/api?timeout=32s\": dial tcp 10.233.0.1:443: connect: no route to host"
F0919 16:30:59.378480 1 server.go:207] unable to set up overall controller manager: Get "https://10.233.0.1:443/api?timeout=32s": dial tcp 10.233.0.1:443: connect: no route to host
出现这个奇怪的ip,我们可以通过ip a命令查找网卡,可以看到这个虚拟ip网段是k8s生成的。
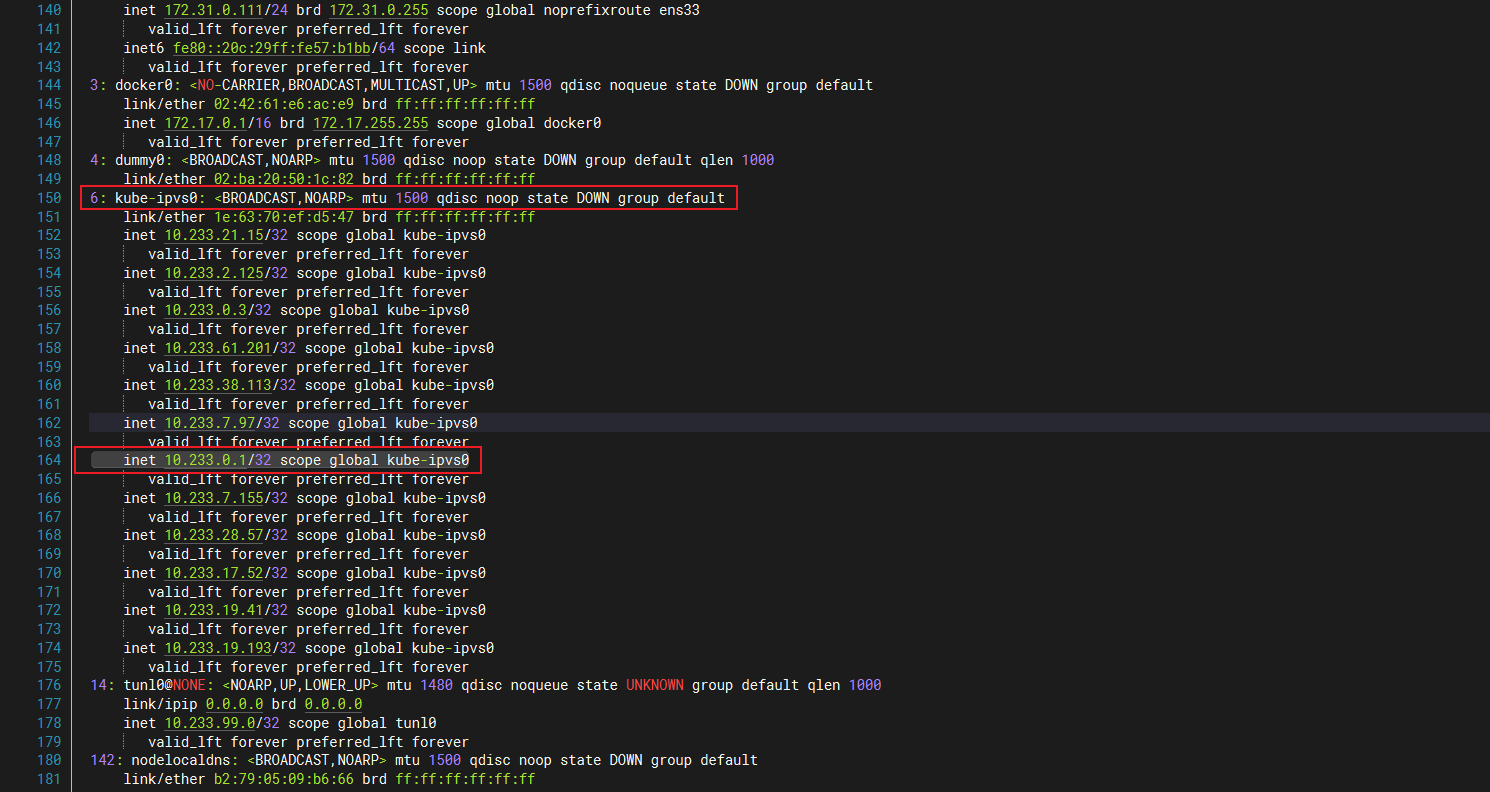
此情况我们可以通过清空防火墙来让kubelet重新添加刷新,执行完稍等一会就能恢复正常了。
iptables -P INPUT ACCEPT
iptables -P FORWARD ACCEPT
iptables -P OUTPUT ACCEPT
#超谨慎使用
iptables -F5. 操作总结
脚本的值还是有点抽象的,具体轮到你如果操作失败可以留言我帮你看看。
评论